Documenten clusteren/classificeren op basis van tekst klinkt redelijk eenvoudig om daarvoor een algoritme te ontwikkelen. Maar wat doen we met documenten waar niet genoeg tekst uit te halen valt, of waar helemaal geen tekst in voor komt? Denk bijvoorbeeld aan gescande ID-kaarten, logo plaatjes, of Excel documenten/tabellen met voornamelijk cijfers. Als mens zijnde zien we de gelijkenis meteen tussen dit soort bestanden, maar een computer helaas niet.
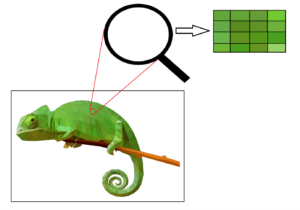 Documenten die weinig tot geen tekst bevatten, en de tekst die ze wel bevatten is casus specifiek, kunnen niet makkelijk bij elkaar worden gezocht. Door middel van een vergelijking op pixel niveau, waar bevind zich welke kleur, kunnen wij ook dit soort documenten bij elkaar zoeken in een ongestructureerde dataset.
Documenten die weinig tot geen tekst bevatten, en de tekst die ze wel bevatten is casus specifiek, kunnen niet makkelijk bij elkaar worden gezocht. Door middel van een vergelijking op pixel niveau, waar bevind zich welke kleur, kunnen wij ook dit soort documenten bij elkaar zoeken in een ongestructureerde dataset.